from datasets import load_dataset
dataset = load_dataset("wikitext", "wikitext-2-raw-v1")LeJEPA Implementation for Text
As a follow up to my previous blog post, I want to implement a LeJEPA architecture adapted for text. The original LeJEPA paper focuses on vision tasks, using a latent prediction approach where the model learns to predict representations of masked image patches from visible context.
In this post, I’ll adapt these principles to text by implementing a transformer-based encoder that predicts latent representations of masked text spans. The key idea is to use span masking - masking contiguous chunks of text rather than random tokens - which encourages the model to learn higher-level semantic representations.
Approach
I’ll implement a LeJEPA-style architecture with:
- An encoder that processes visible text tokens.
- A predictor that learns to predict the target encoder’s representations of masked spans.
The goal is to train this model from scratch on a text dataset and evaluate how well the learned representations capture semantic information. This is primarily an implementation exercise to better understand how the LeJEPA architecture works and how it can be adapted beyond vision tasks.
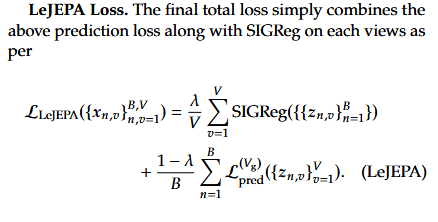
For this we’ll need to create functions and classes for: - A LeJEPAText class that defines the LeJEPA architecture. - A LeJEPATextDataModule class that loads and preprocesses the text data.
And use: - A text dataset, for which I’ll use a standard dataset from HuggingFace. - A tokenizer, for which I’ll use a standard open source tokenizer.
Data
Investigating the Dataset
prompt / response
What would be a good dataset to use for this? Please search the web
🤖Reply🤖
🧠🧠🧠🧠🧠🧠🧠🧠🧠
For a text LeJEPA self-supervised learning experiment, here are some good dataset options:
Best for this experiment:
FineWeb / FineWeb-Edu - * Includes 15T tokens of cleaned and deduplicated English web data. * The dataset focuses on cleaner, more informative content that actually helps models learn language patterns, reasoning, and structure. That is why it has become a popular choice for pretraining and fine-tuning large language models.
WikiText-103 - A classic choice for self-supervised text experiments. Clean Wikipedia articles with ~100M tokens - manageable size for experimentation.
OpenWebText - Recreated WebText corpus, good for general text pretraining.
My recommendation for your experiment:
For a blog post / learning exercise, I’d suggest WikiText-103 (wikitext-103-raw-v1) because: - Manageable size (~100M tokens) - Clean, well-structured text - Fast to download and iterate with - Standard benchmark for language modeling
from datasets import load_dataset
# Quick to download, good for experimentation
dataset = load_dataset("wikitext", "wikitext-103-raw-v1")If you want something larger later, you can use HuggingFaceFW/fineweb-edu with streaming:
# For larger scale (streaming to avoid downloading all 15T tokens)
dataset = load_dataset("HuggingFaceFW/fineweb-edu", split="train", streaming=True)Would you like me to help set up the DataModule for WikiText-103?
investigation
dataset["train"][:5]{'text': ['',
' = Valkyria Chronicles III = \n',
'',
' Senjō no Valkyria 3 : Unrecorded Chronicles ( Japanese : 戦場のヴァルキュリア3 , lit . Valkyria of the Battlefield 3 ) , commonly referred to as Valkyria Chronicles III outside Japan , is a tactical role @-@ playing video game developed by Sega and Media.Vision for the PlayStation Portable . Released in January 2011 in Japan , it is the third game in the Valkyria series . Employing the same fusion of tactical and real @-@ time gameplay as its predecessors , the story runs parallel to the first game and follows the " Nameless " , a penal military unit serving the nation of Gallia during the Second Europan War who perform secret black operations and are pitted against the Imperial unit " Calamaty Raven " . \n',
" The game began development in 2010 , carrying over a large portion of the work done on Valkyria Chronicles II . While it retained the standard features of the series , it also underwent multiple adjustments , such as making the game more forgiving for series newcomers . Character designer Raita Honjou and composer Hitoshi Sakimoto both returned from previous entries , along with Valkyria Chronicles II director Takeshi Ozawa . A large team of writers handled the script . The game 's opening theme was sung by May 'n . \n"]}prompt / response
Hmmm… it looks like in this dataset the text is split between documents. How can I deal with this in a dataset for training a text JEPA?
investigation
from transformers import AutoTokenizer
from torch.utils.data import Dataset
from tqdm import tqdm
class ChunkedTextDataset(Dataset):
def __init__(self, dataset, tokenizer, max_length=128):
# Concatenate all non-empty text
all_text = " ".join([t for t in tqdm(dataset["text"]) if t.strip()])
# Tokenize everything at once
tokens = tokenizer(all_text, return_tensors="pt", add_special_tokens=False)["input_ids"].squeeze()
# Chunk into fixed-length sequences (drop remainder)
num_chunks = len(tokens) // max_length
self.chunks = tokens[:num_chunks * max_length].view(num_chunks, max_length)
def __len__(self):
return len(self.chunks)
def __getitem__(self, idx):
return {"input_ids": self.chunks[idx]}tokenizer = AutoTokenizer.from_pretrained("gpt2")# Concatenate all non-empty text
all_text = " ".join([t for t in tqdm(dataset["train"]["text"]) if t.strip()]) 0%| | 0/36718 [00:00<?, ?it/s] 31%|███ | 11260/36718 [00:00<00:00, 112588.56it/s] 62%|██████▏ | 22673/36718 [00:00<00:00, 113488.47it/s] 93%|█████████▎| 34085/36718 [00:00<00:00, 113774.77it/s]100%|██████████| 36718/36718 [00:00<00:00, 113158.42it/s]# Tokenize everything at once
tokens = tokenizer(all_text[:1000000], return_tensors="pt", add_special_tokens=False)["input_ids"].squeeze()Token indices sequence length is longer than the specified maximum sequence length for this model (219671 > 1024). Running this sequence through the model will result in indexing errorslen(all_text), len(tokens)(10916756, 219671)prompt / response
Can you change the tokenizer above to run a batched way? right now it appears to be crashing on the whole dataset
investigation
from transformers import AutoTokenizer
from torch.utils.data import Dataset
from tqdm import tqdm
import torch
class ChunkedTextDataset(Dataset):
def __init__(self, dataset, tokenizer, max_length=128, batch_size=10000):
# Filter non-empty text
texts = [t for t in dataset["text"] if t.strip()]
# Tokenize in batches
all_tokens = []
for i in tqdm(range(0, len(texts), batch_size), desc="Tokenizing"):
batch = texts[i:i + batch_size]
encoded = tokenizer(batch, add_special_tokens=False)["input_ids"]
for ids in encoded:
all_tokens.extend(ids)
tokens = torch.tensor(all_tokens)
# Chunk into fixed-length sequences
num_chunks = len(tokens) // max_length
self.chunks = tokens[:num_chunks * max_length].view(num_chunks, max_length)
def __len__(self):
return len(self.chunks)
def __getitem__(self, idx):
return self.chunks[idx]
# Usage
tokenizer = AutoTokenizer.from_pretrained("gpt2")
train_dataset = ChunkedTextDataset(dataset["train"], tokenizer, max_length=256)
print(f"Number of chunks: {len(train_dataset)}")Tokenizing: 0%| | 0/3 [00:00<?, ?it/s]Tokenizing: 33%|███▎ | 1/3 [00:00<00:00, 2.24it/s]Tokenizing: 67%|██████▋ | 2/3 [00:00<00:00, 2.87it/s]Tokenizing: 100%|██████████| 3/3 [00:00<00:00, 4.11it/s]Tokenizing: 100%|██████████| 3/3 [00:00<00:00, 3.55it/s]Number of chunks: 9343train_dataset[0]tensor([ 796, 569, 18354, 7496, 17740, 6711, 796, 220, 198, 2311,
73, 13090, 645, 569, 18354, 7496, 513, 1058, 791, 47398,
17740, 357, 4960, 1058, 10545, 230, 99, 161, 254, 112,
5641, 44444, 9202, 25084, 24440, 12675, 11839, 18, 837, 6578,
764, 569, 18354, 7496, 286, 262, 30193, 513, 1267, 837,
8811, 6412, 284, 355, 569, 18354, 7496, 17740, 6711, 2354,
2869, 837, 318, 257, 16106, 2597, 2488, 12, 31, 2712,
2008, 983, 4166, 416, 29490, 290, 6343, 13, 44206, 329,
262, 14047, 44685, 764, 28728, 287, 3269, 2813, 287, 2869,
837, 340, 318, 262, 2368, 983, 287, 262, 569, 18354,
7496, 2168, 764, 12645, 278, 262, 976, 21748, 286, 16106,
290, 1103, 2488, 12, 31, 640, 11327, 355, 663, 27677,
837, 262, 1621, 4539, 10730, 284, 262, 717, 983, 290,
5679, 262, 366, 17871, 5321, 366, 837, 257, 23634, 2422,
4326, 7351, 262, 3277, 286, 7096, 544, 1141, 262, 5498,
1898, 6839, 1810, 508, 1620, 3200, 2042, 4560, 290, 389,
46852, 1028, 262, 11773, 4326, 366, 2199, 321, 265, 88,
12552, 366, 764, 220, 198, 383, 983, 2540, 2478, 287,
3050, 837, 6872, 625, 257, 1588, 6903, 286, 262, 670,
1760, 319, 569, 18354, 7496, 17740, 2873, 764, 2893, 340,
17383, 262, 3210, 3033, 286, 262, 2168, 837, 340, 635,
25289, 3294, 16895, 837, 884, 355, 1642, 262, 983, 517,
43486, 329, 2168, 29661, 764, 15684, 11915, 371, 4548, 64,
8835, 73, 280, 290, 26777, 7286, 13704, 13231, 43354, 1111,
4504, 422, 2180, 12784, 837, 1863, 351, 569, 18354, 7496,
17740, 2873, 3437, 33687, 5303, 18024])Data Loading and Preprocessing
Okay so I’ve got a dataset and a tokenizer. However, I think we need some further changes to the dataset, so that we can use it for training. To apply JEPA here, we need a “source” batch of tokens and a “target” batch of tokens, where we train the joint representations to be equivalent.
I’m thinking a good way to do this to split texts in the tokenizer __getitem__ method. This will probably need a min_split_size and max_split_size to avoid splits being overly large or small.
prompt / response
Is the approach that I’m suggesting above sensible? Is there anything I might be missing?
One thing I’m wondering is if having different splits as inputs to the model will have an impact on positional encoding.
prompt / response
Yeah, that makes sense. That being said I don’t think we need the positional key here, as that can be generated in the model.
Can you start by sketching out the generate_span_mask logic? I think I want this so that it splits into 2 spans at a random index, with a min length to avoid splits that are too small for the model to learn.
Try and make this minimal… I essentially just want a boolean mask based on a random index between min_length and seq_len - min_length
prompt / response
I like version one of this. Can you now integrate this into the dataset logic.
prompt / response
I’m now happy with how this is splitting and chunking.
Can you create a pytorch lightning data module for processing this data?
Model
Next, we need to define the model. There’s a few things to work out here: - How to apply SIGReg. - Defining an encoder that can encoder both the source and target spans. - Defining a predictor that can predict the target encoder’s representations of masked spans.
SIGReg
prompt / response
To start, I want to work out how to implement SIGReg. Can you implement this, referencing both the paper and this implementation on github. If easier I’m happy for you to use the github implementation directly.
Encoder Model
prompt / response
Thanks. Now, how can we build the encoder model. I want a transformer based text encoder that can get representations of the source and targets, with masking based on the source/target split. We’ll also need a predictor that predicts the target from the context?
I initially was under the impression that the target encoder would be a copy of the source encoder that is updated as a moving average. However it appears from re-reading the LeJEPA paper that SIGReg supposedly removes the need for EMA. I can also see that other and other JEPA implementations, e.g. this repo, aren’t using stop gradients. I’m going to go ahead using the same encoder for source and target, however I will check for collapse (i.e. encoder producing constant vectors), as this is known to be an issue with JEPA architectures.
Because I’m working in an environment with limited compute, I think it would be better for the predictor just to be a linear layer, rather than a transformer.
Lets do this bit by bit, starting with creating an encoder and showing how we can get source and target representations in a batched way. I think the challenge here is that batches of sources and targets will be inconsistent lengths. If possible I think we should deal with this through passing the mask when we get representations.
Can you use the code here https://github.com/jerber/lang-jepa/blob/main/src/encoder/models.py and here https://github.com/jerber/lang-jepa/blob/main/src/encoder/train.py as inspiration, particularly how the masking is applied. I’m happy for the positional encoding to be a simple embedding layer.
prompt / response
The mask here is unused in the encoder here which I’m finding a bit confusing. Can you confirm if a TransformerEncoder in pytorch can see ahead if there is no mask… i.e. can value in position 10 see the value in position 11?
prompt / response
But in this context you pass both the source and target through the encoder without a mask, so surely the context values will be able to see the target values and visa versa. I can see in https://github.com/jerber/lang-jepa/blob/main/src/encoder/train.py on line 136 and 144/145 that the source and target are masked, but in your version no masking is applied
Full Class
prompt / response
Okay, I think I’m happy with this now. Can you now combine these previous steps into a full LightningModule?
Initiate and Check Model
import torch
import torch.nn as nn
import pytorch_lightning as pl
class TextEncoder(nn.Module):
"""Simple transformer encoder for text."""
def __init__(self, vocab_size, embed_dim=256, num_heads=4, num_layers=4, max_length=512, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.token_embedding = nn.Embedding(vocab_size, embed_dim)
self.position_embedding = nn.Embedding(max_length, embed_dim)
self.dropout = nn.Dropout(dropout)
encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim,
nhead=num_heads,
dim_feedforward=embed_dim * 4,
dropout=dropout,
batch_first=True,
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, input_ids, attention_mask=None):
B, L = input_ids.shape
positions = torch.arange(L, device=input_ids.device).unsqueeze(0).expand(B, -1)
x = self.token_embedding(input_ids) + self.position_embedding(positions)
x = self.dropout(x)
if attention_mask is not None:
src_key_padding_mask = (attention_mask == 0)
else:
src_key_padding_mask = None
x = self.transformer(x, src_key_padding_mask=src_key_padding_mask)
return self.norm(x)
class LinearPredictor(nn.Module):
def __init__(self, embed_dim):
super().__init__()
self.proj = nn.Sequential(
nn.Linear(embed_dim, embed_dim),
nn.LayerNorm(embed_dim),
)
def forward(self, x):
return self.proj(x)
class LeJEPAText(pl.LightningModule):
def __init__(
self,
vocab_size=50257,
embed_dim=256,
num_heads=4,
num_layers=4,
max_length=512,
dropout=0.1,
lr=1e-4,
sigreg_weight=0.1,
num_slices=1024,
):
super().__init__()
self.save_hyperparameters()
# Shared encoder for context and target
self.encoder = TextEncoder(
vocab_size, embed_dim, num_heads, num_layers, max_length, dropout
)
self.predictor = LinearPredictor(embed_dim)
self.sigreg = SIGReg(num_slices=num_slices)
self.lr = lr
self.sigreg_weight = sigreg_weight
def get_representations(self, input_ids, target_mask):
"""Get context and target representations with proper masking."""
context_mask = ~target_mask
# Context: only attend to context positions
context_hidden = self.encoder(input_ids, attention_mask=context_mask)
context_hidden = context_hidden * context_mask.unsqueeze(-1).float()
context_repr = context_hidden.sum(dim=1) / context_mask.sum(dim=1, keepdim=True).float()
# Target: only attend to target positions (no gradient)
with torch.no_grad():
target_hidden = self.encoder(input_ids, attention_mask=target_mask)
target_hidden = target_hidden * target_mask.unsqueeze(-1).float()
target_repr = target_hidden.sum(dim=1) / target_mask.sum(dim=1, keepdim=True).float()
return context_repr, target_repr
def forward(self, input_ids, target_mask):
context_repr, target_repr = self.get_representations(input_ids, target_mask)
predicted_repr = self.predictor(context_repr)
return predicted_repr, target_repr, context_repr
def compute_loss(self, batch):
input_ids = batch["input_ids"]
target_mask = batch["target_mask"]
predicted_repr, target_repr, context_repr = self(input_ids, target_mask)
# MSE loss between predicted and actual target representations
prediction_loss = nn.functional.mse_loss(predicted_repr, target_repr)
# SIGReg on context representations to prevent collapse
sigreg_loss = self.sigreg(context_repr)
total_loss = prediction_loss + self.sigreg_weight * sigreg_loss
return total_loss, prediction_loss, sigreg_loss, context_repr
def training_step(self, batch, batch_idx):
total_loss, pred_loss, sigreg_loss, context_repr = self.compute_loss(batch)
# Monitor for collapse
repr_std = context_repr.std(dim=0).mean()
self.log("train/loss", total_loss, prog_bar=True)
self.log("train/pred_loss", pred_loss)
self.log("train/sigreg_loss", sigreg_loss)
self.log("train/repr_std", repr_std, prog_bar=True)
return total_loss
def validation_step(self, batch, batch_idx):
total_loss, pred_loss, sigreg_loss, context_repr = self.compute_loss(batch)
repr_std = context_repr.std(dim=0).mean()
self.log("val/loss", total_loss, prog_bar=True)
self.log("val/pred_loss", pred_loss)
self.log("val/sigreg_loss", sigreg_loss)
self.log("val/repr_std", repr_std)
return total_loss
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=self.lr)model = LeJEPAText(vocab_size=50257, embed_dim=64, num_heads=2, num_layers=2)
num_params = sum([p.numel() for p in model.parameters()])
print("Number of Parameters:", num_params)Number of Parameters: 3353600%%time
context_repr, target_repr = model.get_representations(**batch)
context_repr, target_reprCPU times: user 8.3 s, sys: 844 ms, total: 9.15 s
Wall time: 385 ms(tensor([[-0.5128, -0.0883, 0.1644, ..., 0.2210, 0.1130, 0.1568],
[-0.5430, -0.2594, -0.1270, ..., 0.1448, -0.0542, 0.1635],
[-0.3083, 0.1464, -0.0937, ..., 0.0654, 0.2852, -0.1501],
...,
[-0.4473, -0.1915, -0.1485, ..., 0.2285, -0.2723, -0.1203],
[-0.4323, -0.1273, 0.0560, ..., 0.1686, -0.0838, 0.1050],
[-0.4209, 0.0393, -0.0346, ..., 0.1213, -0.0704, 0.1748]],
grad_fn=<DivBackward0>),
tensor([[-0.4988, -0.0431, 0.3527, ..., 0.1180, 0.1283, 0.0995],
[-0.4808, -0.0066, -0.0075, ..., 0.1063, 0.0564, 0.1553],
[-0.3580, -0.0674, 0.0278, ..., 0.1353, 0.0917, 0.1066],
...,
[-0.4294, 0.0062, -0.1615, ..., 0.3190, -0.1362, 0.2172],
[-0.4899, -0.2853, -0.0208, ..., 0.0021, 0.0751, 0.3868],
[-0.5488, 0.0648, 0.0065, ..., -0.0263, 0.0421, 0.1304]]))%%time
predicted_repr = model.predictor(context_repr)
predicted_reprCPU times: user 38.5 ms, sys: 0 ns, total: 38.5 ms
Wall time: 1.06 mstensor([[ 0.5477, -0.7017, -0.2800, ..., 1.4106, -0.6975, -0.2430],
[-0.1500, -1.1685, 0.4107, ..., 0.1386, -1.0401, 0.6272],
[ 1.0390, -1.0849, -0.7849, ..., 0.4333, -0.6909, 0.9622],
...,
[-0.3853, -1.1286, 0.0256, ..., -0.0637, -0.9749, 0.4740],
[ 0.5579, -1.2967, -0.4796, ..., 0.5714, -0.5915, 0.4055],
[ 0.4296, -0.5910, -0.1715, ..., 0.2881, -1.1545, 0.4743]],
grad_fn=<NativeLayerNormBackward0>)%%time
prediction_loss = nn.functional.mse_loss(predicted_repr, target_repr)
prediction_lossCPU times: user 489 μs, sys: 20 μs, total: 509 μs
Wall time: 348 μstensor(1.1227, grad_fn=<MseLossBackward0>)%%time
sigreg_loss = model.sigreg(context_repr)
sigreg_lossCPU times: user 38.1 ms, sys: 0 ns, total: 38.1 ms
Wall time: 2.25 mstensor(0.8375, grad_fn=<MeanBackward0>)Train
Now, lets use a lightning trainer and fit the model
Conclude
Above we have a minimal implementation of LeJEPA on text. This has definately helped with my understanding of how JEPA architectures work, and I think could provide a good foundation for further implementations of LeJEPA for text domains.
There would be quite a few things I would want to do next, including:
- Scale up the model and dataset.
- Add proper logging and training monitoring.
- Downstream evaluations on text classification datasets.
- Add a decoder and use this for text generation.
Building this has been a pain. A couple of key issues:
- The LLM doesn’t understand JEPA well and has made basic mistakes in the implementation. Most of the prompts above have come from multiple revisions, and my own rewrites after double checking other implementations and the LeJEPA paper. I suppose because it’s a relatively new technique that it isn’t widely seen in the training data.
- solveit keeps crashing as I’m running. I think this is just because compute is limited and it’s running out of memory. In the future for these kinds of tasks I’ll want to use a GPU, which will either involve working locally or working out to SSH into a cluster while in solveit (potential follow up post!).
As a next step to this, I’m keep to implement this more comprehensively. I’ve relied quite a lot on this repo, and it could be interesting to try and add LeJEPA in here, while potentially also adding evaluation so that we can compare LeJEPA to the repos original implementation, and with other text encoders.